Written by Harry Fairhead
From http://www.i-programmer.info/babbages-bag/301-assemblers-compilers-and-interpreters.html?start=1
Perhaps the most important single invention of the assembler era was the symbolic address.
The main part of an assembler was a symbol lookup table that came pre-loaded with all of the mnemonics and their corresponding machine code equivalents.
Given you have a symbol table why not make more use of it? Machine code programmers have no choice but to write absolute addresses in their programs. For example:
MOV AL,0001H
means load the
In most cases the programmer doesn’t actually care that memory location 0001H is used. The actual address is generally irrelevant as long as it is used consistently.
That is, if you stored the pay rate in memory location 0001H then the next time you make use of the pay rate it should be fetched from memory location 0001H, but if you had used memory location 0002H instead of 0001H then that would be fine also – as long as you always used memory location 0002H when you wanted to use the pay rate.
For most tasks the exact memory location that you use to store some data is irrelevant - as long as it is always used consistently. In the early days programmers would have to start their programs by performing manual memory allocation. that is they first assigned uses to particular memory locations - 001 will be the total, 002 the running count, 003 a temporary result and so on. Then as they programmed the action of the program they used the addresses that had been assigned in instructions
Clearly trying to remember where you stored everything isn’t fun and it’s very error prone.
The assembler idea, and its symbol table, can help again. Instead of using absolute memory addresses why not use symbolic addresses?
That is use symbols in your programs that the assembler replaces with consistent addresses that it assigns.
For example, you might write something like:
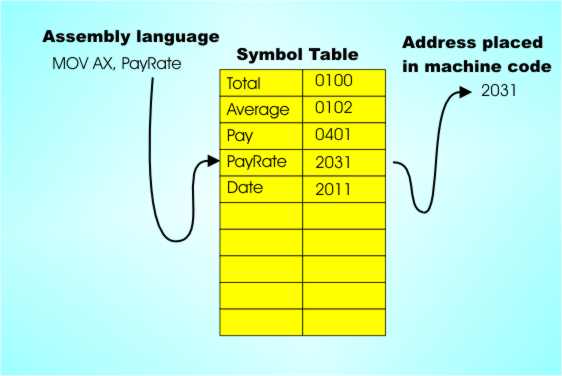
PayRate DB 100H
MOV AL,PayRate
Here the first line isn’t a program instruction – it is an assembler declaration. It says that the symbol “PayRate” is to be considered to be a particular byte in memory, i.e. DB = Declare Byte. When the programmer writes in the next line MOV AL,PayRate it means replace PayRate with the actual address that it was allocated.
Notice now that the assembler has taken on a new role in life – it is allocating memory! When the assembler translates the program to machine code it has to keep a table that tells it what address “PayRate” corresponds to and it has to allocate an address to “PayRate” when it meets its declaration for the first time.
In fact this idea is too good to leave there and not only can the “DB” assembler directive tell it to allocate memory it also can tell it what to initialise that memory to - 100H in this example. So when the MOV AL,PayRate instruction is obeyed not only does this load
To implement this use of symbolic addressing the assembler has to have a slightly more sophisticated symbol table and back in the early days many a computer science course would spend hours on hash tables and other techniques for fast lookup of symbols. Today lookup tables are a solved problem – unless you’re discussing millions and millions of symbols!
A slightly more sophisticated symbol table – one that can be added to – gives us variables
What is really important here is that the move to a symbolic representation has once again distanced us from the machine code.
Now we have something that looks quite sophisticated and is just one step away from the idea of a “variable”, a key concept in the development of all computer languages.
You can start to forget about “addressing” and the physical hardware that makes the machine work. Instead you can start to think about creating variables – named units of storage – like PayRate that you can simply use in your program without any worry about where they are actually stored.
The elaboration of the “variable” idea gave rise to the first high-level computer language – Fortran.
Oddly assembly languages didn’t just take the totally abstract approach. Even today, if you want to use assembler then staying close to the machine’s hardware must be important to you. As a result assembly language programmers have found ways of making their products just abstract enough to make them easier to use but without reducing the efficiency of the program or the ability of the programmer to make things happen exactly as required.
So, as well as direct symbolic addressing, most assembly languages have a whole range of different types of addressing that can be used to access data. For example, register relative addressing, as in:
MOV AX,[BX]+10
means move the contents of the memory location who's address is given by adding 10 to the contents of the BX register, into register AX.
Notice that the square brackets generally mean – the “address given by”. This sort of notation eventually developed into the high-level language concept of an array of variables.
For example, you might write PayRate[10] to mean the 10th variable in the PayRate array which would translate more or less directly to [BX]+10. Oddly the concept of an array, or any sophisticated data structure, never caught on as part of an assembler – presumably because it was a step too far away from the hardware.
Assemblers slowly developed additional features and one of the most powerful is the idea of the macro. A macro is simply a block of text that you can insert into a program by specifying its name. So if you keep using the same block of assembler you can save a lot of effort by defining a macro for it and using that. Of course things can get much more sophisticated. Macros soon developed parameters so you could write reusable blocks of code that could be customized when used.
Today most assemblers are "macro" assemblers and they even come with lots of predefined macros that make assembler closer to a high level language. However the key fact is that to be an assembler it must be possible for the programmer to get back to the lowest possible level - the assembly language that is very close to the way the machine actually works.
** End of Page